3 The Transformer in a Nutshell
Transformers use vectors in their “embedding space” (this space is \(\mathbb{R}^n\), typically for \(n\) in the thousands) to represent “thoughts” (a semantic meaning, a concept, an idea). Just as we know that, at a mechanical level, our brains represent thoughts as patterns of synapses firing, a transformer is mechanically just composing and transforming these vectors.
They “think” by performing operations on these thought vectors that transform and compose them into other meanings, which are represented by some other coordinates in the embedding space.
3.1 Visual Walkthrough
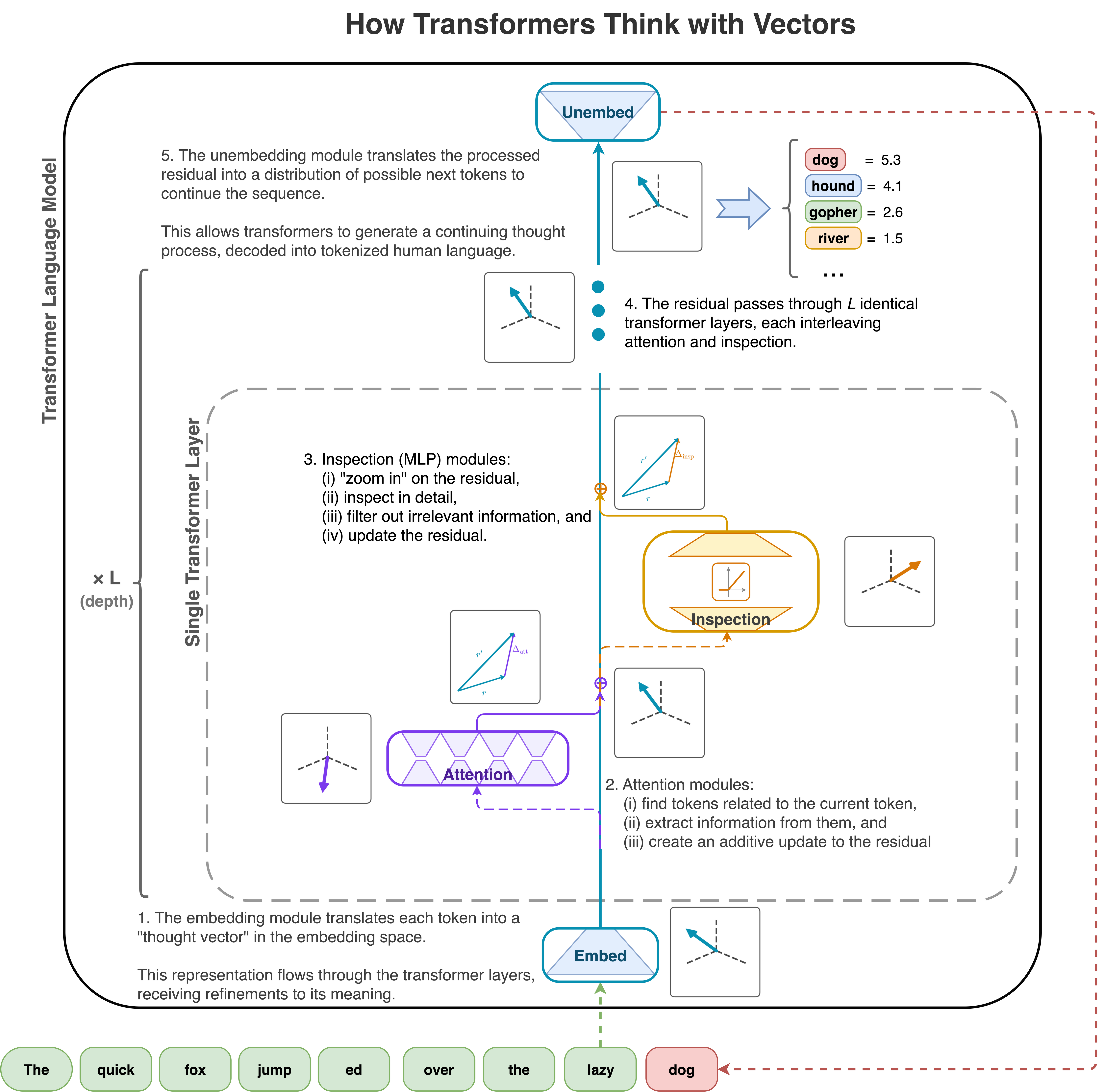
3.2 Four operations
Transformers receive an input sequence of text and generate a continuation by performing just four fundamental operations involving thought vectors (embedding space semantic representations).
- Embed: They convert text into thought vectors – i.e. a sequence of vectors in the embedding space. This is precisely analogous to humans hearing or reading a word and holding the concept in their mind via some synapse pattern. The embedding matrix performs this operation.
- Attention: They identify relationships among thought vectors in a sequence (context window), and move information among the related tokens. This is accomplished by the attention layer.
- Inspection: They “inspect” thought vectors. They magnify, probe, and filter information from thought vectors, then add updates to the thought vector to encode this information before passing the embedding to the next layer. This is done by the MLP (aka feed forward or linear) layer.
- Unembed: They convert thought vectors into text. The “inverse” of the embed operation. To be precise, it converts a “thought vector” embedding into a (logit) distribution over tokens, but a simple argmax reduces this to the most likely token. The unembedding matrix performs this translation to tokens.
The first and last translate to and from human text and are used once each as the first and last steps in processing a token. All of the “thinking” that occurs within the “mind” of the transformer comes from repeated composition of the attention and inspection operations. The transformer is able to bootstrap a remarkable artificial intelligence by composing (only!) the two core “thinking” operations interleaved for many layers, bookended by translations from and to human language text.
3.3 Transformer Training
We have seen that a transformer is a long chain of “layers” each one takes in the residual (a “thought vector”) from the previous layer, performs these attention and inspection operations, which somehow update the meaning in the thought vector, and then pass it on to the next layer. The next layer does the same type of process, but with different values of the matrix entries used in those operations. It is also bookended by embedding and unembedding layers that translate from (tokenized) human text, to thought vectors, and then back from thought vectors to text.
Each of these operations involves matrix operations that transform all these intermediate vector space representations. Since the spaces have thousands of dimensions, these matrices have millions of parameters each. Each parameter can be thought of as a “knob” that will fine-tune the behavior of that matrix operation. Altogether, a transformer typically has many billions of these knobs, and somehow we need to fine-tune all of them in unison to get our mechanical brain to “think” in a reasonable and useful way. This is a daunting task, but calculus comes to the rescue.